Kyle-
That is what I was expecting, that after some time to get the ewon box back up, it would reach out again. The server is still configured to have the tags available, etc.
Yes, I am using primary WAN Ethernet (spectrum cable modem), and a AT&T 4G LTE cellular fallback.
I am not sure the reason of the IP Conflict, other than we were trying to troubleshoot our network. Our Access Points only have one DHCP Server possible, and we have an internal network for the automation system which is 191.168.72.0/21. I know its not standard, but its a result of how we outgrew our existing network and we didn’t want to change a ton of IP addresses. So this is what we ended up keeping. Anyway, our AP’s have two SSID’s, each on its own VLAN. One VLAN is for the internal automation network, and the other is for the Internet access. Due to having to share a DHCP Server (one is allowed per AP), the IP’s it hands out have to work on both sides. The VLAN keeps the segregation.
Anyway, we were trying to put our iPad on the internet SSID, and use eCatcher to get into the LAN (demonstrating eWon and eCatcher to new employees). Well that is when I started running into IP Conflicts, etc. Which makes total sense. So we can’t do that here. If I had a seperate DHCP Server for each SSID, then it wouldn’t be an issue. But these are industrial Wifi AP’s, that apparently don’t allow for this. We have stopped doing this now, but still all the devices get an IP in this range, and we still have the VLAN keep the segregation.
The eWon WAN is having an IP outside this subnet, which it gets from a Firewalla Gold firewall box, which itself connects to the Spectrum cable modem. We set up a 3rd VLAN on our network to send this over the 1G fiber line to the managed switch and then to the eWon WAN port.
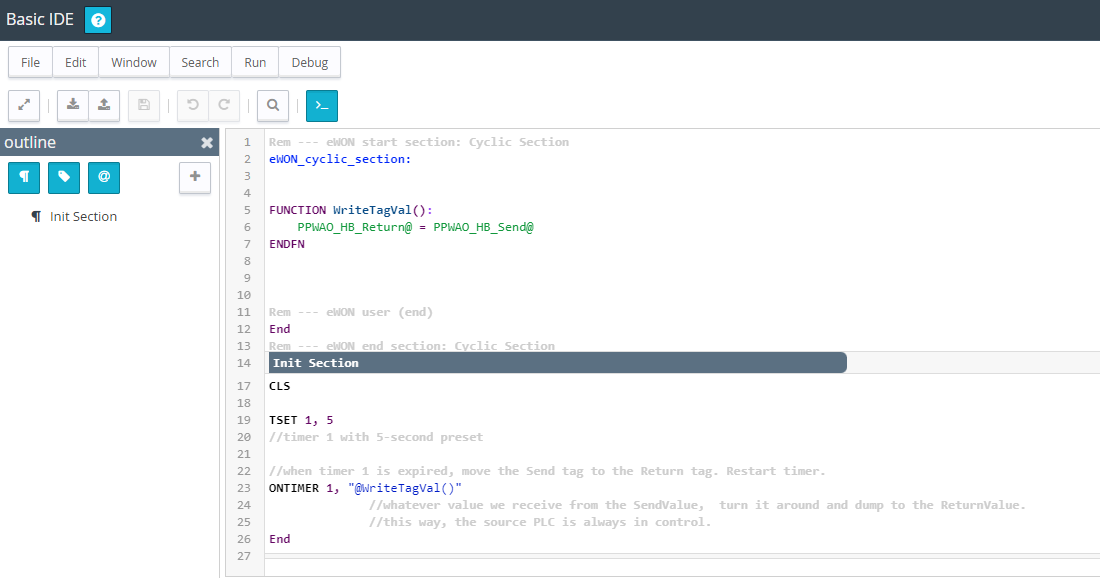
I also did some reconfiguration with the IO Servers-> Advanced Parameters-> Default TCP RX/TX Timeout, I changed it to 10000 mSec. And left unchecked the Disable Tags in Error. This has helped with some of the errors I was getting. Just now, the eWon rebooted itself due to unknown reason. And once again the tag values are all unknown. Even after several minutes. Per the forums suggestion, I just did an Init on the two IO Servers I am using, and am waiting for the tag values to resume good status. The Real Time logs show the OPCUA disconnect, then connecting, then connected. But the tag values are not ok still. And even the S7300&400 IO server, which uses the ISO-On-TCP, that is not updating either.
I do have a new backup I can send if needed?
07/02/2023 09:25:22 -20205
muting (pattern of 2 events)
ftps
07/02/2023 09:23:58 -20205
muting (pattern of 3 events)
opcuacom
07/02/2023 09:23:58 -20205
pattern of 1 event muted 4 times
config_writer
07/02/2023 09:23:52 -20205
muting (pattern of 1 event)
opcuaiosrv
07/02/2023 09:23:52 -38320
opcuaiosrv-Waiting session disconnection
opcuaiosrv
07/02/2023 09:23:52 -38320
opcuaiosrv-Waiting session disconnection
opcuaiosrv
07/02/2023 09:18:32 -38320
opcuaiosrv-Waiting session disconnection
opcuaiosrv
07/02/2023 09:18:31 -38308
opcuaiosrv-OPCUA service error (BadTimeout)
opcuacom
07/02/2023 09:18:30 -31130
wanmgt-WAN connection request failed: DHCP
wanmgt
07/02/2023 09:18:09 -22602
System Booting, FWR: 14.6s0 (14.6), SN: 1804-0031-24 [EF0000]
elog
06/02/2023 04:42:52 -31166
wanmgt-WAN Fallback – Maximum duration reached using fallback interface
wanmgt
06/02/2023 03:42:51 -31167
wanmgt-WAN Fallback – Switching to fallback interface
wanmgt
06/02/2023 03:42:51 -31163
wanmgt-WAN Fallback – Could not access test servers using primary connection ((03/03) – tcp://device.api.talk2m.com:443)
wanmgt
06/02/2023 03:41:51 -31163
wanmgt-WAN Fallback – Could not access test servers using primary connection ((02/03) – tcp://device.api.talk2m.com:443)
wanmgt
06/02/2023 03:40:51 -31163
wanmgt-WAN Fallback – Could not access test servers using primary connection ((01/03) – tcp://device.api.talk2m.com:443)
wanmgt
06/02/2023 03:25:31 -31166
wanmgt-WAN Fallback – Maximum duration reached using fallback interface
wanmgt
06/02/2023 02:25:30 -31167
wanmgt-WAN Fallback – Switching to fallback interface
wanmgt
06/02/2023 02:25:30 -31163
wanmgt-WAN Fallback – Could not access test servers using primary connection ((03/03) – tcp://device.api.talk2m.com:443)
wanmgt
06/02/2023 02:24:30 -31163
wanmgt-WAN Fallback – Could not access test servers using primary connection ((02/03) – tcp://device.api.talk2m.com:443)
wanmgt
06/02/2023 02:23:29 -31163
wanmgt-WAN Fallback – Could not access test servers using primary connection ((01/03) – tcp://device.api.talk2m.com:443)